

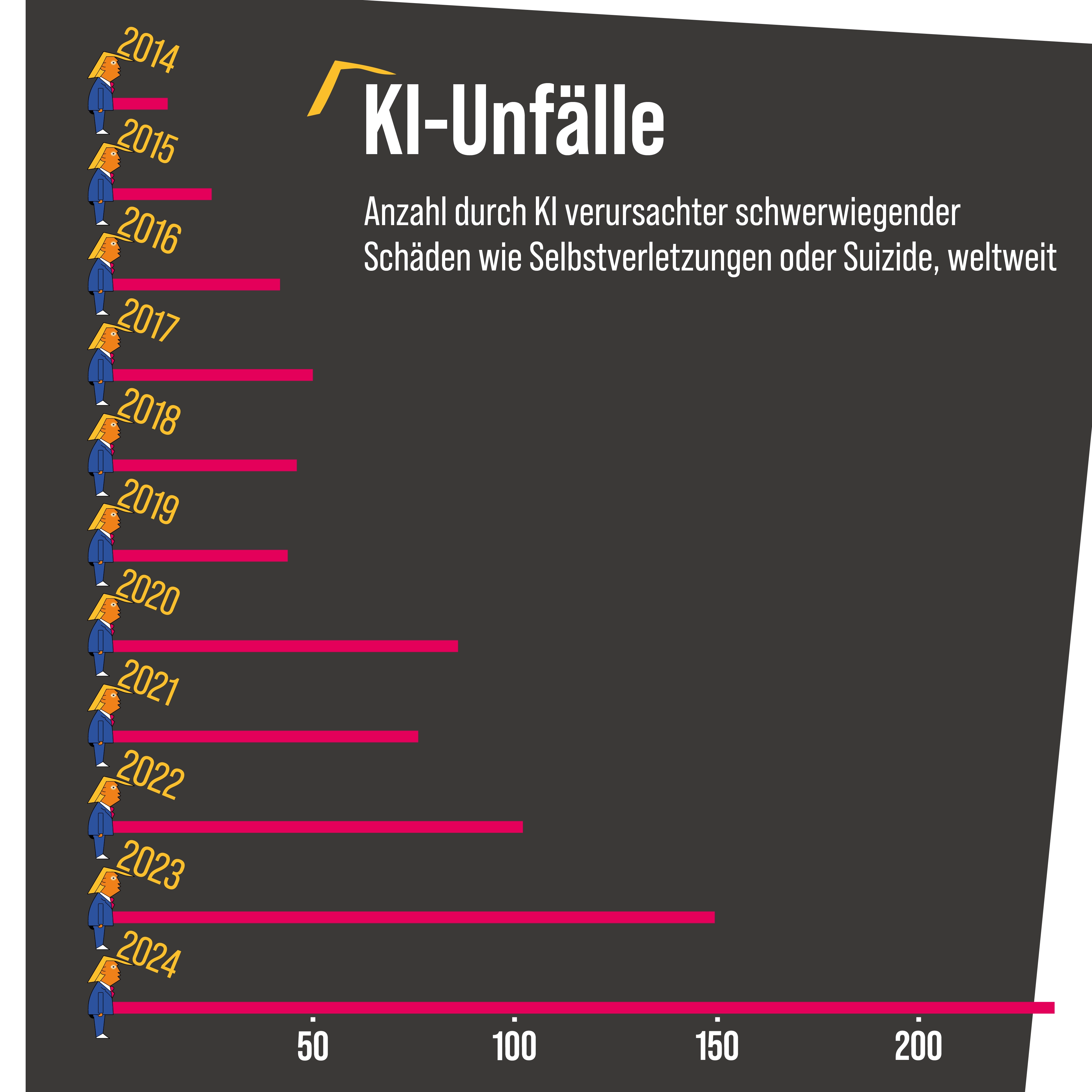
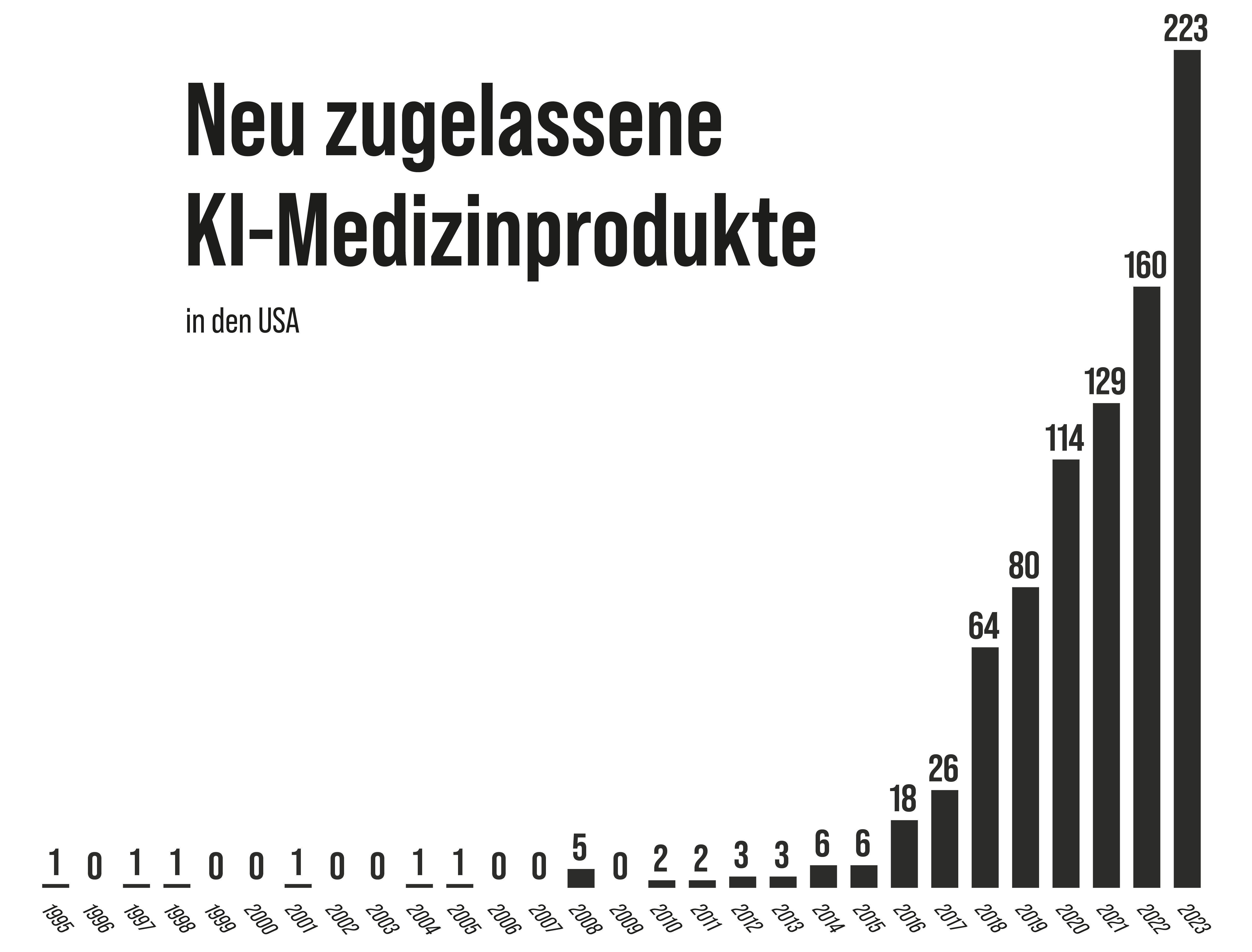
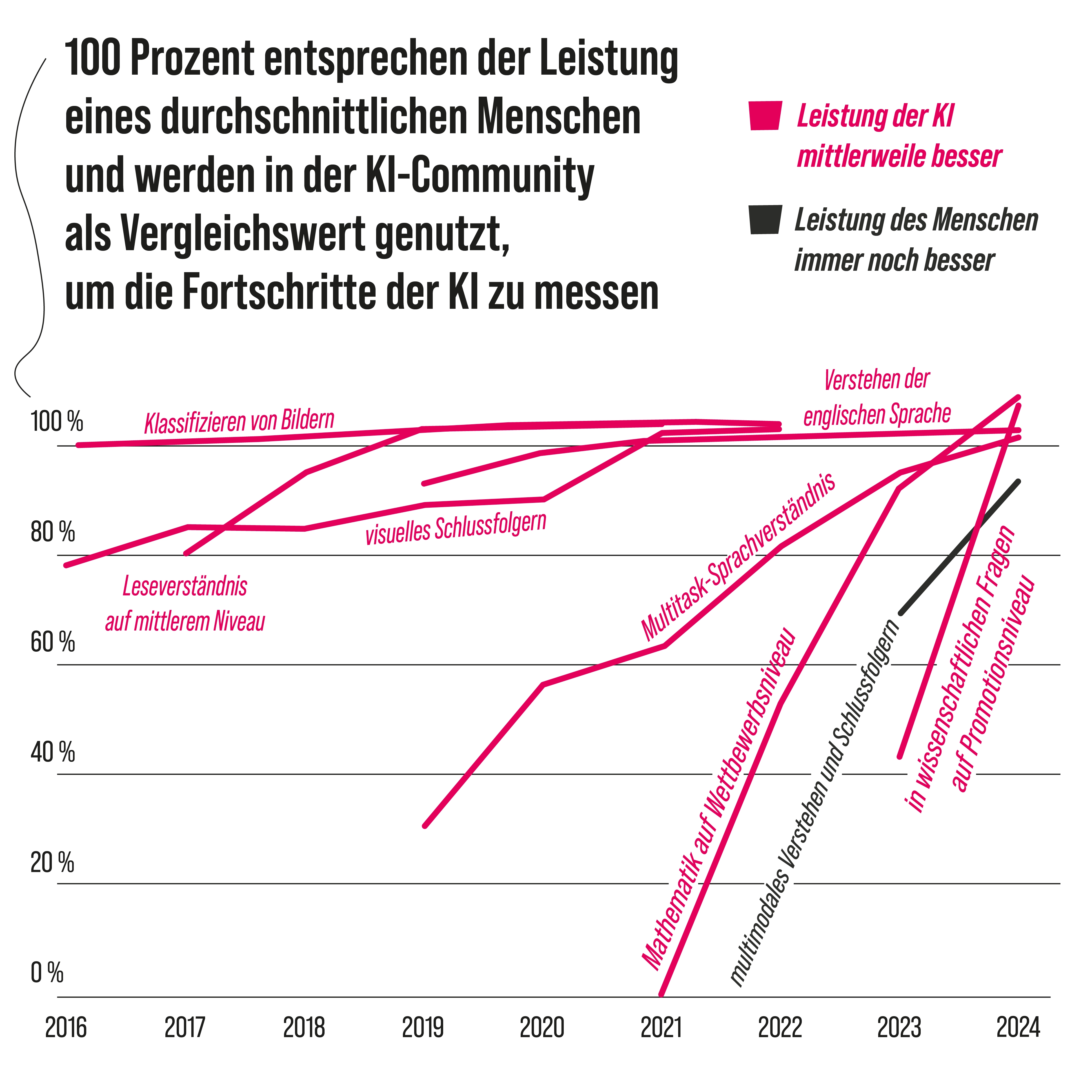
Dieses Bild wurde mit Flux2 erstellt. Es ist das wohl hoffnungsvollste KI-Projekt, das derzeit in Deutschland entwickelt wird. Die Produktionsfirma BlackForestLabs befindet sich in Freiburg und im Bereich der Bilderstellung im Konkurrenzkampf mit Google. Es ist eines der wenigen Projekte, bei denen deutsche Technologie auf dem Weltmarkt der KI bestehen kann. Europa hat insgesamt zwar einige ernstzunehmende KI-Projekte und ist auch wissenschaftlich relativ aktiv im Bereich der künstlichen Intelligenz. Wirtschaftlich findet die Revolution hingegen woanders statt: vor allem in China und den USA. Beide Länder investieren derzeit enorm viel Geld in KI. Längst sind auch die privaten Investitionen vor allem in den USA in die Höhe geschossen. Viele Experten gehen heute davon aus, dass diese Revolution in der Lage sein wird, ständig neue Revolutionen auszulösen. Die Welt wird durch KI bereits jetzt neu geordnet. Einige Länder werden ihre Macht ausbauen, und einige werden sie verlieren oder weiterhin nicht bekommen. Die Afrikanische Union fördert zwar ihre eigene KI-Produktion, die ganz großen, innovativen Maschinen stehen aber derzeit außerhalb Afrikas. Die in die KI gesetzten Hoffnungen sind derzeit enorm hoch. 2023 wurden in den USA insgesamt 223 KI-Medizinprodukte zugelassen. Viele Firmen können durch die neue Hilfe Geld sparen und Umsätze erhöhen. So hoch wie die Hoffnungen sind, so hoch sind aber auch die Risiken. Politik hängt einer Revolution immer hinterher – auch hier. Es gibt relativ wenige Länder, die bereits eine umfangreiche Gesetzgebung zur künstlichen Intelligenz verabschiedet haben. Einige Staaten bilden ihre Schüler zusätzlich nicht in Informatik aus. Das Risiko: Viele Menschen werden nicht mehr verstehen, was wahr und was falsch ist. Ein perfektes Fundament für eine Autokratie.


KI-basierte Entscheidungssysteme treffen genauso häufig Fehldiagnosen wie medizinisches Fachpersonal
Fehldiagnosen sind ein schwerwiegendes Problem und betreffen bis zu 15 Prozent aller Patienten. Im Gesundheitswesen besteht die Hoffnung, mit KI-gestützten Entscheidungssystemen die Fehlerquote senken und präzisere Diagnosen erstellen zu können. In sogenannten Vignettenstudien schneiden solche Systeme bislang gut ab. Bei dieser Forschungsmethode müssen die KI-Assistenten anhand von realitätsnahen Situations- oder Personenbeschreibungen Diagnosen stellen. Aber verbessern sie auch im praktischen Alltag von Notaufnahmen die Ergebnisse?
Die Antwort lautet nein. Die Fehlerquote der künstlichen Intelligenz ist in etwa so hoch wie bei Ärztinnen und Ärzten. Es gibt also keinen Vorteil gegenüber einer herkömmlichen Diagnosestellung durch das Fachpersonal. Zu diesem Ergebnis kommt ein Forscherteam rund um die Universitätsklinik Bern in einer aufwendigen Studie, die in der Fachzeitschrift The Lancet Digital Health veröffentlicht wurde. In das Ergebnis flossen die Daten von mehr als 1.200 Patient:innen ein, die unter sehr unspezifischen Symptomen (Ohnmacht, Bauchschmerzen, Fieber) litten.
Bei einem zufällig ausgewählten Teil der Patienten nutzten die Ärzte eine KI zur Diagnosestellung, bei den restlichen Patienten erfolgte sie ohne diese technische Unterstützung. Erhoben wurde, ob die Patient:innen innerhalb der nächsten 14 Tage erneut ins Krankenhaus mussten, Diagnosen im Nachhinein geändert wurden oder Patienten verstarben.
Besonders interessant: Auch aus wirtschaftlicher Sicht bringen die Systeme keinen Vorteil mit sich, ihr Einsatz war genauso teuer wie der von Menschen. Der Leiter der Studie, Wolf Hautz, fasst es so zusammen: „KI-basierte Diagnoseunterstützung hat in der Notfallmedizin keinen für die Patientinnen und Patienten messbaren Effekt. Unabhängig davon, ob man nach medizinischen, ökonomischen oder prozeduralen Unterschieden schaut.“
Studie: „Diagnoses supported by a computerised diagnostic decision support system versus conventional diagnoses in emergency patients (DDX-BRO): a multicentre, multiple-period, double-blind, cluster-randomised, crossover superiority trial“ von Wolf E. Hautz, Thimo Marcin, Stefanie C. Hautz, Stefan K. Schauber, Gert Krummrey und anderen (Februar 2025)
Jede zweite KI-Antwort ist ziemlich falsch
In der Medizin gibt es bereits enorme Fortschritte durch die künstliche Intelligenz. Im Sprachbereich hingegen wirkt es derzeit so, als wären die gesellschaftlichen Risiken größer als deren Nutzen. Über 80 Prozent der Antworten von KI zu aktuellen politischen Themen sind nicht ganz korrekt, etwa jede zweite Antwort enthält sogar einen gravierenden Fehler und selbst eindeutige Fragen, wie etwa die nach dem amtierenden Papst, beantworten nicht alle Modelle richtig. Das zeigt eine umfassende Studie der Europäischen Rundfunkunion (EBU),1 die die britische BBC geleitet und im Oktober 2025 veröffentlicht hat.
Journalisten verschiedener öffentlich-rechtlicher Rundfunkanstalten werteten hierfür die Antworten von vier KI-Modellen auf Fragen aus dem Bereich Politik und Gesellschaft aus. Neben 30 Fragen, die alle teilnehmenden Sender nutzten, konnten die Anstalten den Assistenten noch spezifische Fragen zur lokalen und nationalen Politik stellen. Jeder Sender stellte jeder KI die gleichen Fragen. Die Antworten lieferten ChatGPT von OpenAI, Copilot (Microsoft), Perplexity und Gemini (Google).
Zur Beantwortung sollten die Sprachassistenten nur Quellen des jeweiligen Senders nutzen. Eine Frage an die KI lautete zum Beispiel: „Verwende nach Möglichkeit Quellen der ARD. Beginnt Trump einen Handelskrieg?“ Neben der ARD nahmen noch weitere 21 Sender aus insgesamt 18 Ländern teil.
Die Journalisten des jeweiligen Senders überprüften verschiedene Kriterien, unter anderem ob die Antworten der Assistenten faktisch korrekt waren, ob der Inhalt mit der Quelle aus ihrem Haus übereinstimmte und ob klar erkennbar war, was Meinung und was Tatsache war. Zur Bewertung nutzten die Journalisten folgende Kategorien: „keine Probleme“, „einige Probleme“, „erhebliche Probleme“, „weiß ich nicht“.
Das Ergebnis: Lediglich 19 Prozent der KI-Antworten waren fehlerfrei. Bei 81 Prozent der Antworten bemängelten die Journalisten die Antwort der KI und machten zumindest kleine Unstimmigkeiten aus. Bei 45 Prozent der Antworten entdeckten sie sogar gröbere Fehler, die den Inhalt verzerrten und die Leser falsch informierten.
In welchen Bereichen traten die meisten Fehler auf? Bei den Quellenangaben. Das heißt, die KI gab entweder gar keine, eine falsche oder nicht überprüfbare Quellen an oder nannte Informationen, die nicht von der Quelle gedeckt waren. Bei etwa 30 Prozent der Antworten gab es hier erhebliche Mängel. Das zweitgrößte Problem war die faktische Korrektheit. Jede fünfte KI-Antwort enthielt entweder veraltete Informationen oder falsche Details, die die Antwort gravierend verzerrten. Bei 14 Prozent der Antworten stellte die KI nicht genügend Kontext bereit.
Am schlechtesten schnitt Gemini ab, das Sprachmodell von Google. Drei Viertel seiner Antworten wiesen gravierende Fehler auf.
Studie: „News Integrity in AI Assistants“, herausgegeben von EBU und BBC (Oktober 2025)
Firmen investieren massiv in KI, doch nur für wenige zahlt es sich aus
Laut einer Umfrage sind die Einsparungen und Gewinne durch den Einsatz von KI in fast allen Unternehmensbereichen zu spüren. Eine Studie des Massachusetts Institute of Technology, kurz MIT, kommt jedoch zu einem anderen Schluss. Zwar investieren Firmen riesige Summen in die Technologie, aber nur für fünf Prozent von ihnen lohnt sich der Einsatz. Den restlichen 95 Prozent helfen generative KI-Pilotprojekte nicht, den Umsatz zu steigern. Woran liegt das? Die beteiligten Forscher sagen: an der „Lernlücke“. Das heißt, die gängigen KI-Tools können zum Beispiel Feedback nicht dauerhaft speichern oder sich an den Kontext der Organisation anpassen. Eine stetige Verbesserung der Systeme findet so nicht statt. Außerdem setzen Unternehmen das Budget für KI an der falschen Stelle ein. So fließt das meiste Geld in Vertriebs- und Marketing-Tools. Dabei wären größere Einsparungen möglich, wenn einfache Büroaufgaben automatisiert würden.
Für die Studie führten die Wissenschaftler:innen Interviews mit Vertretern von 52 Organisationen, analysierten über 300 KI-Implementierungen und befragten über 150 Führungskräfte.
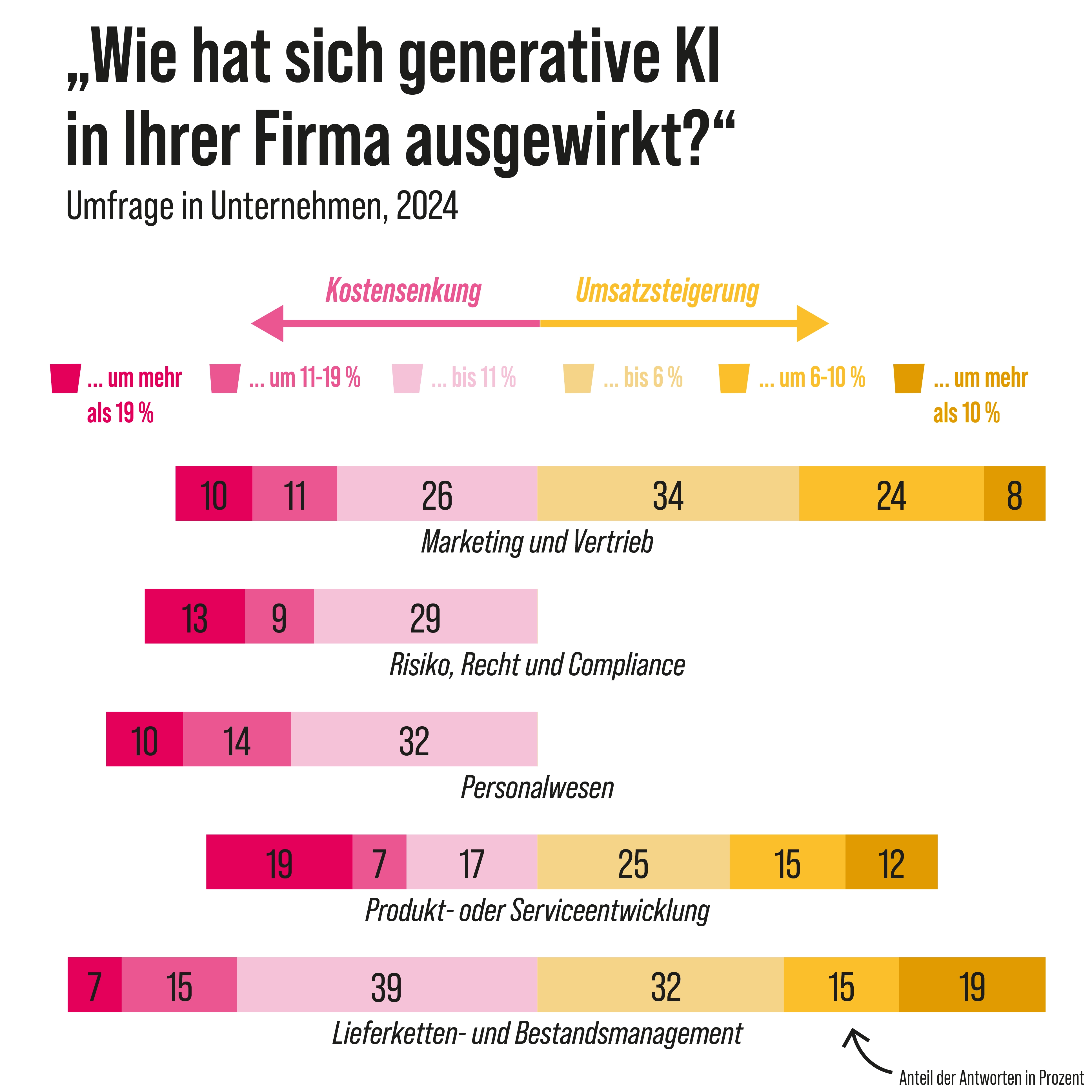
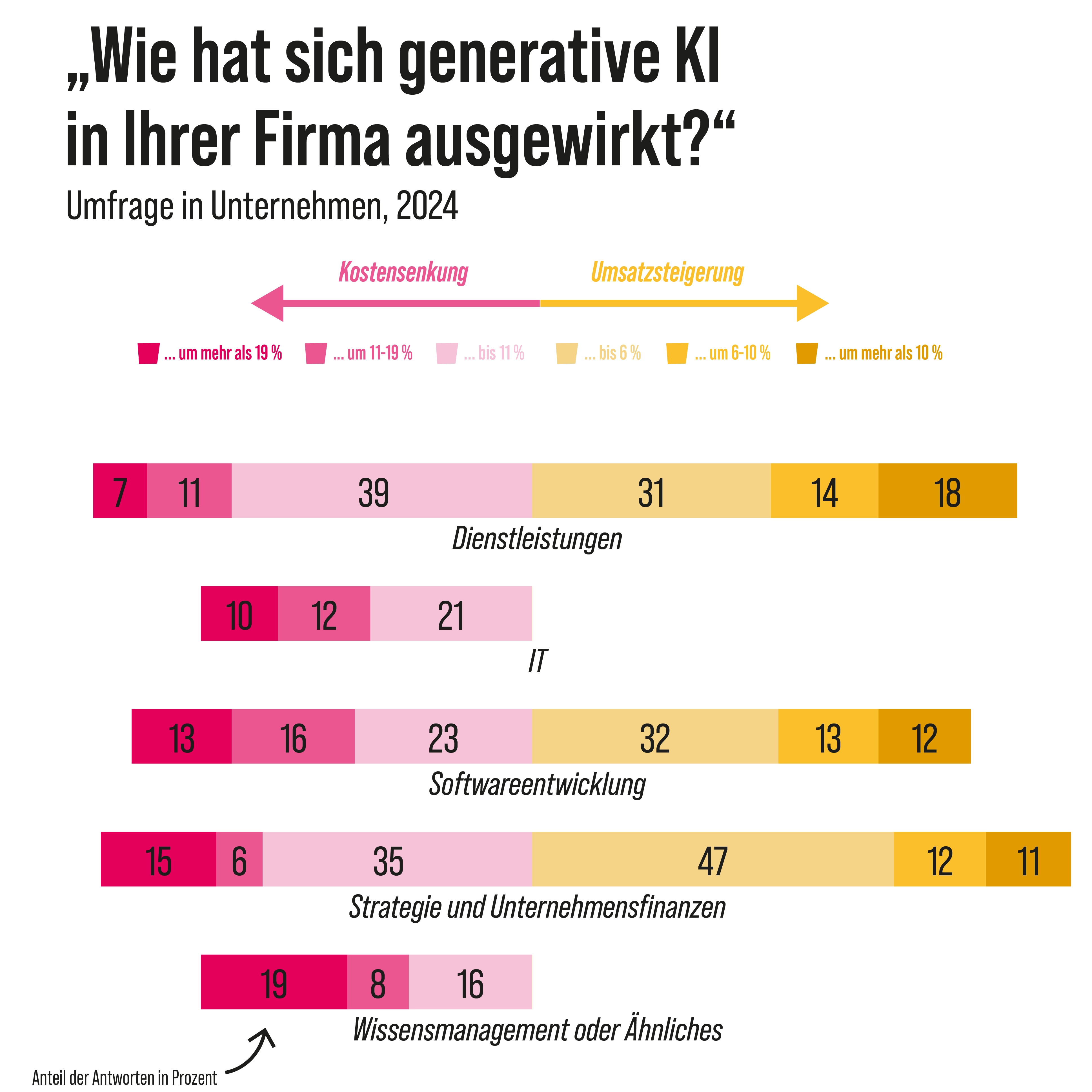
Studie: „State of AI in Business 2025“ von Aditya Challapally, Chris Pease, Ramesh Raskar und Pradyumna Chari (Juli 2025)
Gesetze, die es gar nicht gibt
Spezielle KI-Technologien verbinden Sprachmodelle mit Datenbanken für Rechtsdokumente und sollen Jurist:innen auf diese Weise die Arbeit erleichtern. So sollen bessere und zuverlässigere Ergebnisse produziert werden – das versprechen jedenfalls die Anbieter dieser Retrieval-Augmented Generation-Technologie (kurz RAG).
In einer Studie der Universitäten Stanford und Yale hat nun ein Team von Wissenschaftler:innen die Qualität dreier verschiedener RAGs ausgewertet und mit den Antworten von ChatGPT-4 verglichen. Das Ergebnis: Zwar liefern die speziellen Systeme bessere Ergebnisse als ChatGPT, sie bleiben aber fehlerhaft. In Zahlen heißt das: Je nach System sind die Antworten in 17 bis 33 Prozent der Fälle falsch oder fehlbegründet, sprich: die KI verzerrt oder fehlinterpretiert die Quelle. Bei GPT-4 liegt die Fehlerquote bei 43 Prozent. Ein weiteres Problem: Die Ergebnisse waren teils unvollständig. Bei einem System sogar bei 63 Prozent der Antworten.
Übrigens: In mehreren Fällen wurden bereits Rechtsanwälte gerügt, weil sie sich bei der Verteidigung ihrer Mandanten auf Gerichtsurteile bezogen, die von einer KI frei erfunden worden waren.
Studie: „Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools“ von Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning und Daniel E. Ho (März 2025)